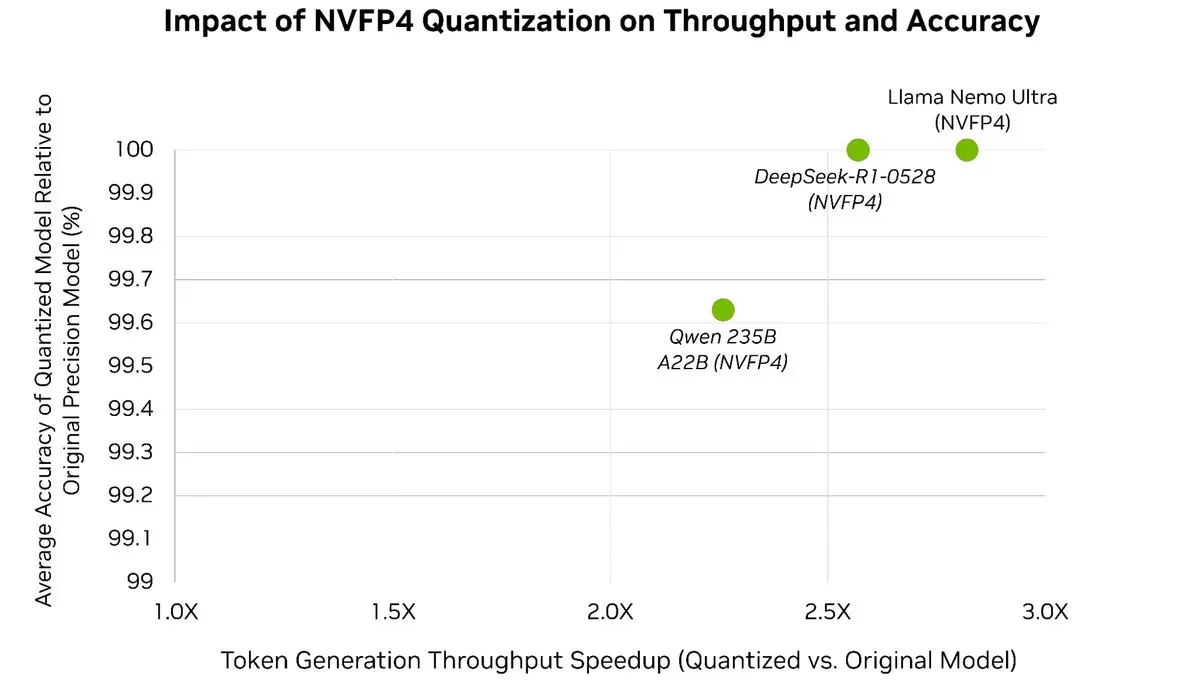
Легко прискорте свої LLM до 3 разів⚡️, зберігаючи понад 99,5% точності моделі 🎯
За допомогою посттренувальної квантизації оптимізатора моделей TensorRT ви можете квантизувати моделі світового рівня до NVFP4, що значно зменшує використання пам'яті та обчислювальні витрати під час інференції, тоді як
Переглянути оригінал