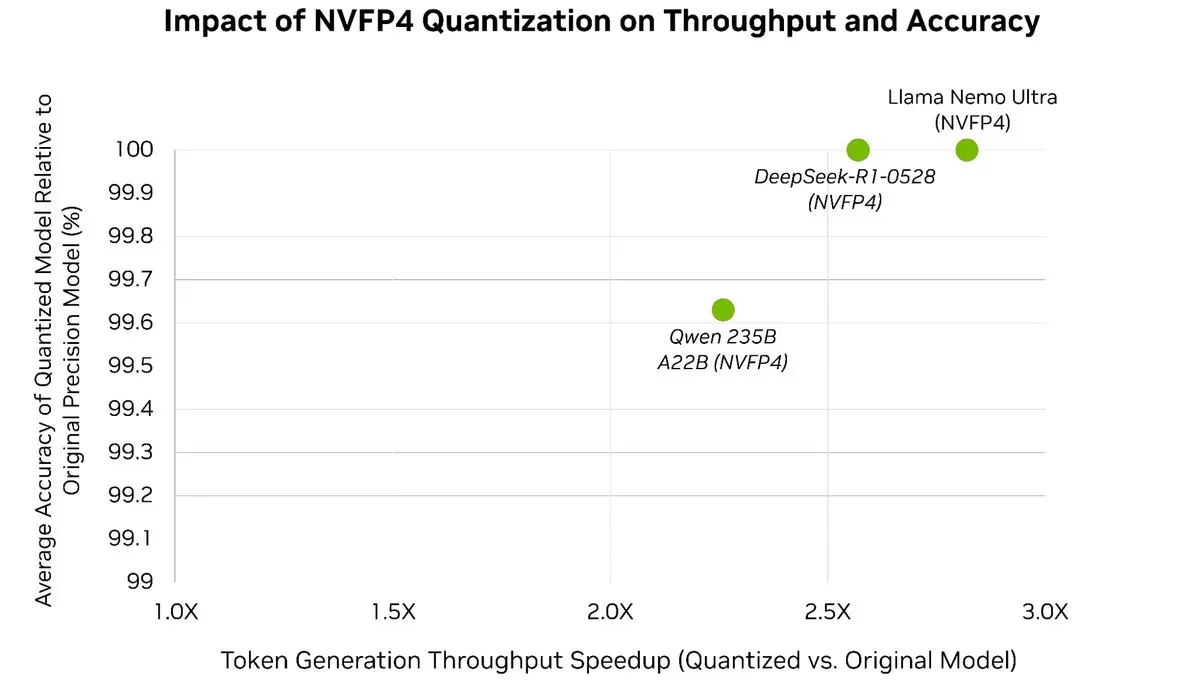
Легко ускорьте свои LLM до 3 раз⚡️, сохраняя более 99,5% точности модели 🎯
С помощью пост-тренировочной квантизации TensorRT Model Optimizer вы можете квантизировать модели передового уровня до NVFP4, что значительно сокращает использование памяти и вычислительные затраты во время вывода, в то время как
Посмотреть Оригинал